如何设置本地 Qsirch RAG
最后修订日期:
2025-10-28
适用产品
Qsirch 6.0.0(或更高版本)在 QuTS hero 平台上
本地 RAG 搜索
对于需要完整数据隐私或离线 AI 的优异用户和企业,Qsirch 在本地托管的 LLM 上运行 RAG。所有操作都在您的 NAS 或连接的硬件上进行——没有数据离开您的环境。
硬件和配置
硬件推荐
- NAS: TS-h1290FX (https://www.qnap.com/zh-tw/product/ts-h1290fx)
- GPUs: RTX 6000 Ada 和 RTX 4000 Ada
- QuTS hero 5.2.1 或更高版本
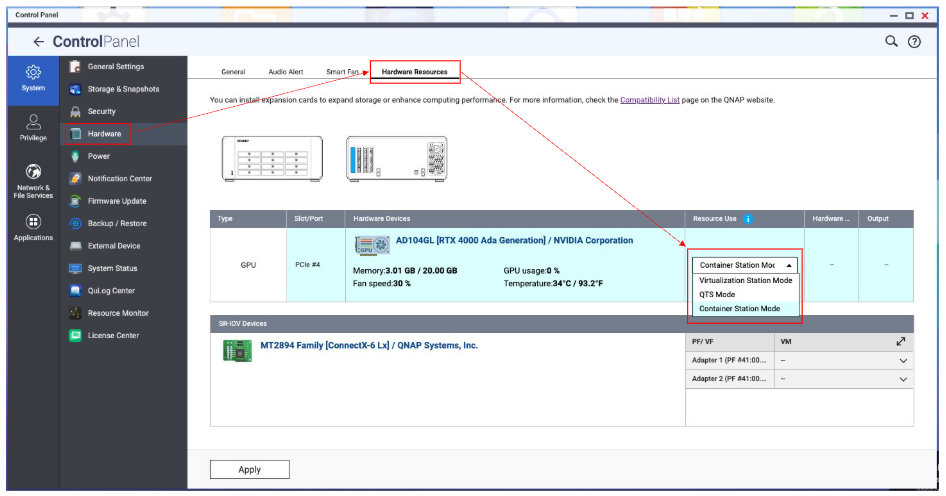
- 已安装并启用 LLM Core
- 前往控制台 > 硬件 > 硬件资源 > 资源使用 > Container Station 模式
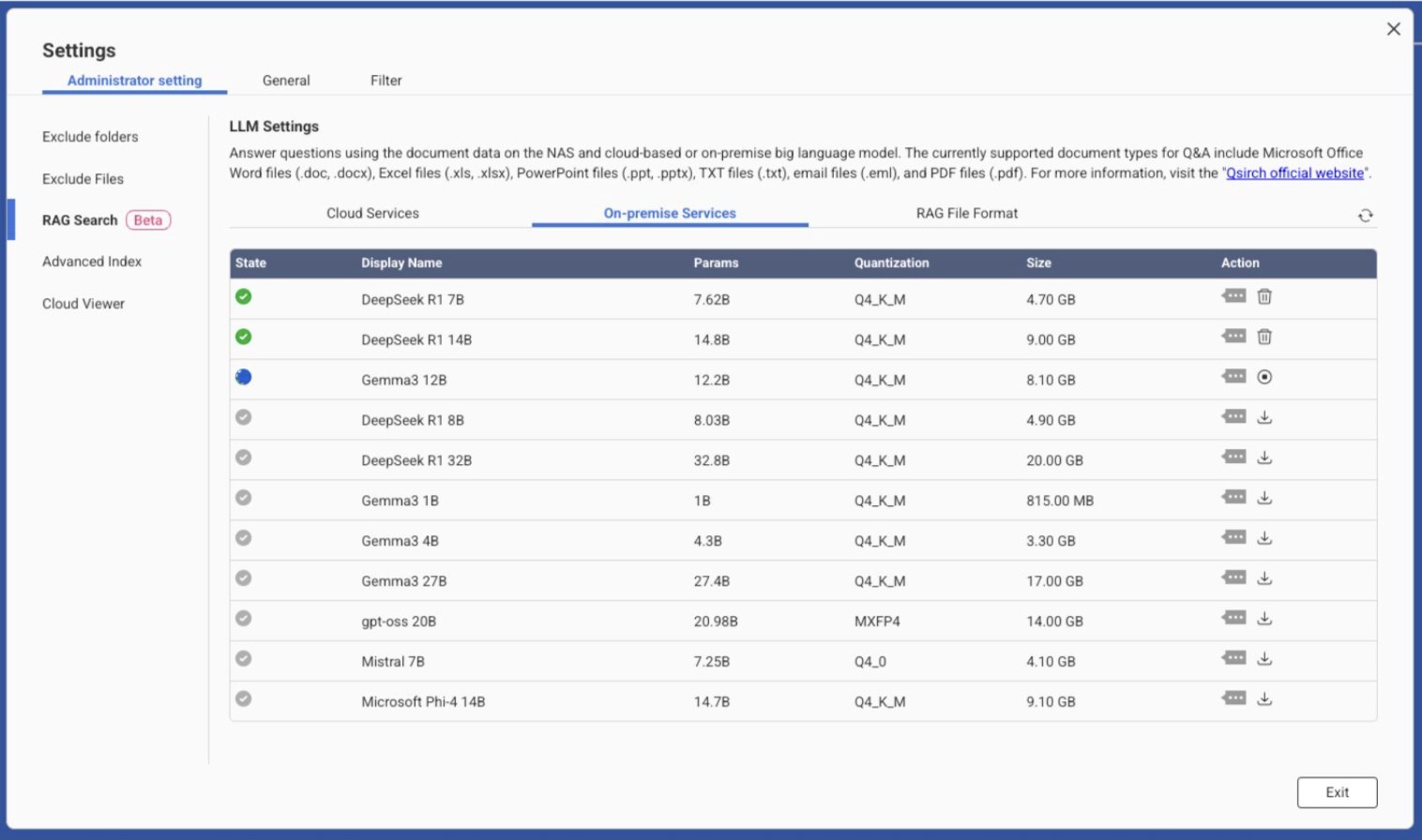
LLM Core(应用程序)- 支持本地 RAG 的模型
LLM Core 将大型语言模型直接带到您的 NAS,让 Qsirch 在不使用云服务的情况下私密高效地运行 RAG。通过内置的模型管理,您可以下载、组织和切换本地模型,然后在 Qsirch 中使用它们进行生成。所有操作都在您的硬件上进行,以控制性能和隐私。
当前支持的本地模型(列表会随时间更新;请在应用程序中查看全新模型):
| 显示名称 | 参数 | 量化 | 大小 |
|---|---|---|---|
| DeepSeek R1 7B | 7.628B | Q4_K_M | 4.70 GB |
| DeepSeek R1 14B | 14.8B | Q4_K_M | 9.00 GB |
| Gemma3 12B | 12.2B | Q4_K_M | 8.10 GB |
| DeepSeek R1 8B | 8.03B | Q4_K_M | 4.90 GB |
| DeepSeek R1 32B | 32.8B | Q4_K_M | 20.00 GB |
| Gemma3 1B | 1.0B | Q4_K_M | 0.815 GB |
| Gemma3 4B | 4.38B | Q4_K_M | 3.30 GB |
| Gemma3 27B | 27.4B | Q4_K_M | 18.00 GB |
| gpt-oss 20B | 20.98B | MXFP4 | 14.00 GB |
| Mistral 7B | 7.25B | Q4_K_M | 4.10 GB |
| Microsoft Phi-4 14B | 14.7B | Q4_K_M | 9.10 GB |
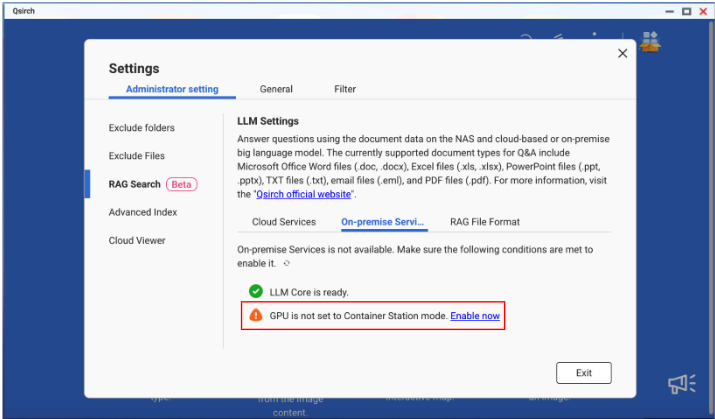
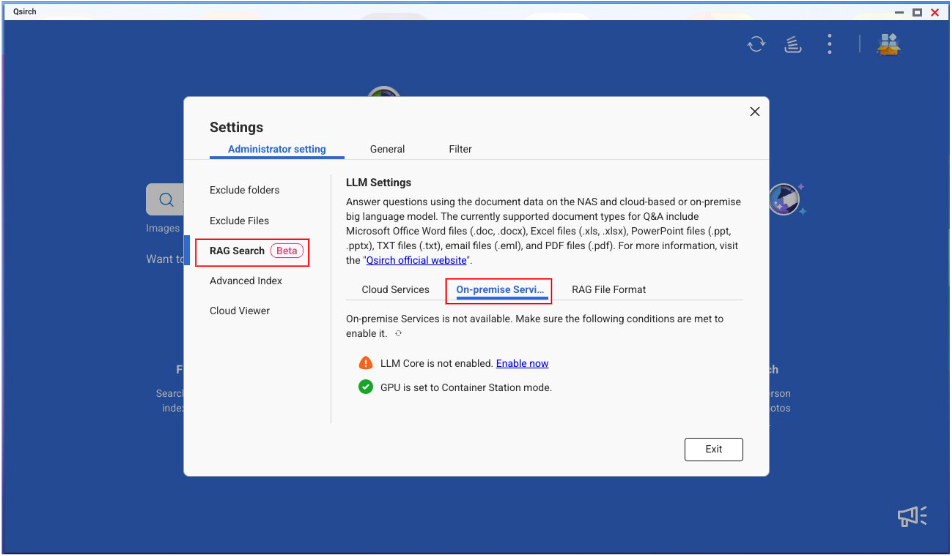
如何在 Qsirch 中设置本地服务
- 前往 设置 > 管理员设置 > RAG 搜索 > 本地服务。
- 如果 LLM Core 未安装 / 启用,请点击 立即启用 以进入 App Center 并安装 / 启用 LLM Core。
如果 GPU 卡未设置为 Container Station 模式,请点击 立即启用 以进入控制台并将 GPU 设置为 Container Station 模式。