QAI-h1290FX
一款支持 NVIDIA® GPU、U.2 NVMe SSD 和 25GbE 连接的 GPU 就绪边缘 AI 存储服务器,专为本地 AI、虚拟化和高计算负载设计。
QAI-h1290FX 是一款桌面级边缘计算与存储融合服务器,结合高性能计算架构与高速存储。支持可配置的 NVIDIA® RTX™ PRO Blackwell GPU,较为适合本地 AI、LLM 推理、私有 RAG 搜索、虚拟化及其他高需求计算任务。
由 QuTS hero 和 ZFS 文件系统驱动,平台提供企业级数据完整性和稳定性能。无论用于 AI 部署、研发、高性能计算还是企业虚拟化环境,QAI-h1290FX 都能实现灵活配置和快速部署,确保关键任务在边缘安全高效运行。




GPU 就绪架构,支持 RTX PRO Blackwell
采用 GPU 就绪设计,支持 NVIDIA® RTX™ PRO Blackwell GPU,包括 RTX PRO 6000 Blackwell Max- Q 工作站等选项,满足 AI 任务、图像生成、推理及 GPU 加速计算需求。
高速全闪 NVMe 存储架构
配备 12 个 U.2 NVMe SSD 盘位,并支持 SATA SSD,可灵活配置存储,优化性能、容量或成本。适用于 AI 任务、虚拟化和实时数据处理。
本地 LLM 与 RAG 搜索
支持私有 LLM 和基于 RAG 的本地部署,实现安全的语义文档检索,无需将敏感数据上传至云端。
基于 ZFS 的 QuTS hero 操作系统
由 QuTS hero 和 ZFS 驱动,提供在线压缩、自修复、快照及 SnapSync,保障企业级数据完整性。
GPU 加速与 AI 应用模板
通过容器工作站实现 GPU 加速。一键部署 Ollama、AnythingLLM、Stable Diffusion 等,简化 AI 应用上线流程。
25GbE 连接与扩展支持
内置双 25GbE 和 2.5GbE 端口,并可升级至 100GbE。通过 QNAP JBODs 扩展,满足不断增长的 AI 数据 存储需求。

QuTS hero 操作系统
荣获 2026 MSP Today 年度产品奖

QNAP QAI-h1290FX
TechRadar Pro Picks Awards CES 2026 获奖产品
QAI 适用场景
-
内部聊天机器人与知识库
使用 AnythingLLM 或 OpenWebUI 部署类似 ChatGPT 的私有机器人。安全连接内部文档,实现员工问答、政策查询和培训支持,无需互联网。

-
私有 RAG 搜索引擎
本地运行检索增强生成(RAG),全面掌控数据。支持自然语言文档搜索,涵盖合同、报告和档案,适用于法律、金融和企业团队。

-
AI 推理与内容生成
使用 Stable Diffusion 或 ComfyUI 进行图像生成,或部署自定义模型实现视频标记、文档摘要和医学分析。受益于 GPU 加速和全闪存存储。

企业级边缘 AI 与高性能计算
QAI-h1290FX 不仅是存储系统,更是具备计算能力的企业级边缘计算平台。基于高性能计算架构,支持可配置的 NVIDIA® RTX™ Pro Blackwell GPU,适用于大语言模型(LLM)推理、图像生成、RAG 搜索以及多种计算密集型和虚拟化工作负载。
无论用于 AI 推理、研发、数据分析,还是企业应用需要高核心数和持续性能,单台桌面级企业平台即可实现出色的计算效率和数据 安全性,全部在本地完成。
高效 AI 计算性能(可选 GPU 配置)

GPU 就绪架构 — 支持 NVIDIA® RTX™ Pro Blackwell
QAI-h1290FX 采用 GPU 就绪架构,专为支持 NVIDIA® RTX™ Pro Blackwell GPU 设计。基于 Blackwell 架构,支持 CUDA、TensorRT 和 Transformer Engine 等加速技术,适用于现代 AI 和 GPU 加速计算工作负载。
从大语言模型(LLM)推理、计算机视觉到生成式 AI 及其他 GPU 加速专业应用,工作负载可在本地部署和执行,实现出色性能,同时保障数据隐私和完整系统控制。该平台还可作为以 CPU 为中心的高性能计算系统,支持虚拟化及多种企业计算场景。
-
 旗舰
旗舰NVIDIA® RTX™ Pro 6000 Blackwell Max-Q 工作站
- 96 GB GDDR7 ECC 内存
- 24,064 CUDA 核心,752 Tensor 核心,188 RT 核心
- 125 TFLOPS(FP32),较高 4000 AI TOPS
- 1,792 GB/s 内存带宽
- 300W 功耗
- PCIe 5.0 x16 接口
-
 性能
性能NVIDIA® RTX™ Pro 4500 Blackwell
- 32 GB GDDR7 ECC 内存
- 10,496 CUDA 核心,328 Tensor 核心,82 RT 核心
- 54.94 TFLOPS(FP32)
- 896 GB/s 内存带宽
- 200W 功耗
- PCIe 5.0 x16 接口
NVIDIA® RTX™ Pro Blackwell 系列 — 重新定义 AI 与高性能计算工作流程
NVIDIA® RTX™ Pro Blackwell 系列 GPU 专为高强度 AI、计算和创意工作负载打造,结合新一代 Blackwell 架构与超快 GDDR7 ECC 内存。单块专业 GPU 提供的计算性能和显存容量,以往需要多块消费级显卡才能实现。
支持较高 96GB 显存和增强的 AI 加速能力,RTX™ Pro Blackwell 系列适用于先进的 LLM、生成模型、数据分析,以及复杂的 3D 可视化和专业计算工作流程。
由服务器级 AMD EPYC™ 处理器驱动,实现高性能计算
QAI-h1290FX 基于服务器级 AMD EPYC 处理器平台,提供高核心数和强大的多线程性能。
专为高度并行工作负载下的长期稳定运行设计,适用于虚拟化、多线程计算、数据处理和边缘计算场景,同时支持 AI 推理及多种计算密集型应用。

采用 QuTS hero 操作系统
专为企业所打造的 QuTS hero 操作系统采用高可靠 ZFS 文件系统,为关键数据存储提供强悍数据安全与系统稳定,更拥有专注于提升 SSD 性能与寿命的先进技术,满足企业对于高性能与可靠度的严苛要求。探索 QuTS hero 操作系统了解 QuTS hero 最新功能
随时随地远程访问本地 AI
通过 QNAP 提供的多种远程访问选项,打造流畅的混合办公环境。无论您是在管理 AI 应用还是访问文件,QAI-h1290FX 都能确保您始终保持连接,同时不会影响安全性。
直接或中继访问选项
- myQNAPcloud DDNS:
通过自定义域名随时随地访问您的 QuTS hero 界面,无需记忆 IP 地址。 - myQNAPcloud Link:
通过 QNAP 服务器建立安全的中继连接,无需开放路由器端口或修改防火墙设置。 - VPN 服务器支持:
使用 QVPN 服务搭建专属 VPN,实现安全加密隧道,全面访问网络。
无论您是在优化 LLM 容器设置、查看推理日志,还是跨地域协作,QAI-h1290FX 都能为您的本地 AI 环境提供可靠访问,支持任何设备随时连接。

更强大的 Container Station:AI 应用部署的新体验
为了推动 AI 的实际应用,QAI 系列将 Container Station 与丰富的 AI 应用模板集成。这些模板支持热门 AI 工具和框架的一键部署,并由 QNAP 定期更新,确保能够使用全新技术。
无论你是 AI 新手还是希望将工作负载迁移到本地,QAI 都能帮助你轻松探索 AI,降低成本,提升数据 安全性,甚至开发定制 AI 工具,助力企业创新。

简化容器化 AI 部署
通过无缝容器集成,提升你的 AI 基础设施。探索容器工作站
以 AI 为核心的容器环境
QAI-h1290FX 配备了 Container Station,支持部署 Docker 和 LXD 容器。由于目前大多数 AI 工具都是以容器化应用形式提供,QAI-h1290FX 为部署如 LLM、RAG 搜索、图像生成(如 Stable Diffusion)或知识库引擎(如 AnythingLLM)等模型提供了直接高效的方式,无需复杂设置。

为 AI 模型提供持久的数据 存储
借助 Docker 卷支持,QAI-h1290FX 允许容器挂载来自 NAS 的共享文件夹,确保即使容器重建后也能保持持久的存储。这对于涉及大型模型文件、训练数据或日志的 AI 工作负载尤其有利。无需再担心在更新或版本切换时丢失关键数据。

让 GPU 加速变得简单,适用于所有 AI 工作负载
QAI-h1290FX 简化了在 Docker 环境中配置 GPU 资源的复杂流程。借助 Container Station 直观的界面,在创建新容器时,只需从下拉菜单中选择所需的 NVIDIA® GPU,容器即可立即获得 GPU 计算能力。无论是部署 LLM、进行图像生成,还是执行深度学习推理,QAI-h1290FX 都能让整个过程更加顺畅高效。

用 AI 驱动的视觉设计重新定义创意
ComfyUI 为艺术家、设计师和内容创作者提供了强大的模块化界面,用于 AI 驱动的图像和视频创作。通过直观的节点式设计和对 Stable Diffusion 等先进模型的支持,用户可以轻松生成、转换和动画化视觉内容。结合 GPU 加速和灵活的工作流程,ComfyUI 降低了复杂视觉设计的门槛,释放了前所未有的创作自由。
真实场景下的 AI 性能——基于 QAI-h1290FX 测量
AI 部署性能通过真实场景基准测试数据进行验证。在高端 GPU 测试配置下,QAI-h1290FX 使用 NVIDIA® RTX™ PRO 6000 Blackwell Max- Q 工作站 GPU 进行了全面评估,验证其在本地 AI 推理和企业部署场景中的表现。
Ollama LLM 推理基准(快速部署)
借助 Blackwell 架构的 GPU 加速能力,QAI-h1290FX 可通过 Ollama 在本地运行多种大语言模型。
Ollama 实现快速部署和简化管理,适用于概念验证(PoC)项目、单用户环境,以及中小规模应用场景,如基于 RAG 的搜索、AI 助手和离线推理。
vLLM 并发推理基准测试(企业级吞吐量)
为满足多用户和高并发 AI 服务需求,QAI-h1290FX 也支持使用 vLLM 推理引擎进行部署。
与面向单请求的推理方式相比,vLLM 通过分页注意力和高效调度机制提升 GPU 利用率和整体吞吐量,较为适合企业 AI 服务、多用户 RAG 系统和基于 API 的 AI 应用。
在相同 GPU 配置下,vLLM 在并发请求场景中展现出更稳定的延迟特性和更高的令牌每秒吞吐量,适用于生产环境和长期企业 AI 部署。
测试的大语言模型:deepseek-ai/DeepSeek-R1-Distill-Qwen-7B(Hugging Face)
测试的大语言模型:openai/gpt-oss-20b(Hugging Face)
通过实际应用场景释放 AI 潜力
从文档自动化到创意流程及系统级自动化,QAI-h1290FX 助力各部门以有意义、可衡量的方式应用 AI——安全托管于您的本地基础设施上。
无云端绑定,无复杂配置——本地 LLM、安全容器和集成 QNAP 功能带来真实成果。
智能人力资源助手——内部政策聊天机器人
使用 AnythingLLM + Ollama 构建内部问答助手。上传员工手册、请假政策、福利等人力资源文件到 QAI-h1290FX。员工可自然提问,例如:
“如何申请家庭护理假?”
系统本地执行 RAG 检索并即时回复,减轻 HR 工作量并提升响应速度。

创意团队 AI 工作室——图像生成中心
设计团队在 QAI-h1290FX 上部署 Stable Diffusion 和 ComfyUI,通过提示输入生成宣传图片、模型图或风格化艺术作品。
借助 GPU 加速和持久的 NAS 存储,设计师可获得快速且可复现的结果,无需重复从头开始。

开发者 AI 协同助手——文档、代码与摘要
工程团队在 QAI-h1290FX 上通过 Ollama 运行 Qwen 或 Llama 等 LLM,协助规范编写、代码审查和技术翻译。
上传 API 文档或白皮书后,可与模型对话获取澄清、摘要或 markdown 格式化——离线且安全。

n8n + NAS 自动化——随时触发 AI
在 QAI-h1290FX 上安装 n8n 后,您可以自动化将 AI 与业务运营集成的任务。例如:

QAI-h1290FX 上的 AI Docker 应用
通过 Container Station 和 GPU 集成运行高效的 AI 解决方案。

将您的 NAS 转变为由 AI 驱动的知识中心
赋能企业用户以更快速度搜索、理解和获取信息——由 Qsirch 和新一代 RAG 搜索提供支持。QAI-h1290FX 为您的文档带来智能,同时确保所有内容安全且本地部署。


边缘 AI 存储服务器对比:
QAI-h1290FX 与其他 AI NAS 与 AI 工作站
选购配件
-

QM2-2P-244A
Dual M.2 22110/2280 PCIe SSD expansion card;
Dimension (L × W × H): 170.5 × 20.6 × 68.9 (mm)
Weight: 0.29 (kg)
Please check the M.2 SSD compatibility list and QM2 Installation Guide
-
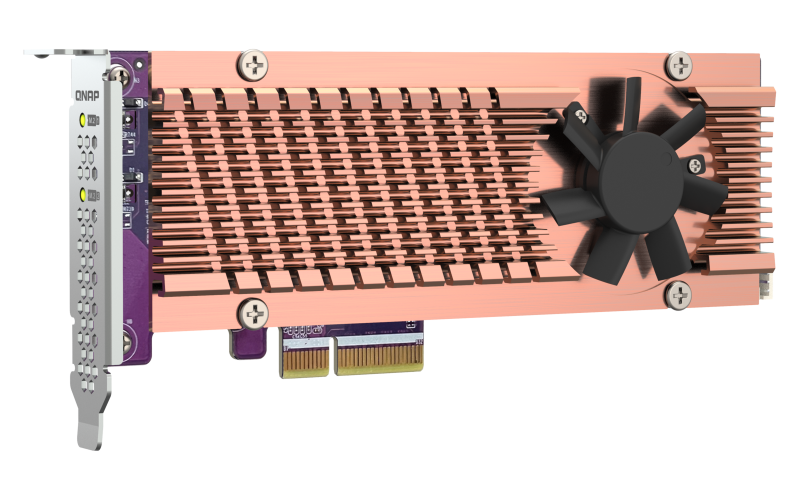
QM2-2P-344A
Dual M.2 PCIe SSD expansion card; M.2 2280/22110 PCIe NVMe(Gen 3x4) SSDs; PCIe Gen3x4 host interface
Dimension (L × W × H): 170.5 × 19.3 × 68.9 (mm)
Weight: 0.30 (kg)
-
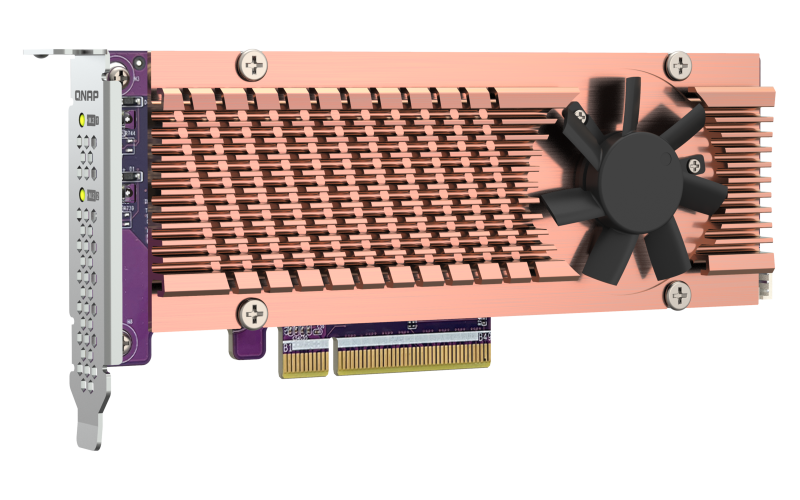
QM2-2P-384A
Dual M.2 PCIe SSD expansion card; M.2 2280/22110 PCIe NVMe(Gen 3x4) SSDs; PCIe Gen3x8 host interface
Dimension (L × W × H): 170.5 × 19.3 × 68.9 (mm)
Weight: 0.30 (kg)
-

QM2-2P10G1TB
QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen3 x 8 , 1 x Marvell AQC113C 10GbE NBASE-T port
Dimension (L × W × H): 152.65 × 18.9 × 68.9 (mm)
Weight: 0.30 (kg)
-
QM2-2P2G2T
QNAP QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen3 x 4 , 2 x Intel I225LM 2.5GbE NBASE-T port
Dimension (L × W × H): 152.65 × 20.6 × 68.9 (mm)
Weight: 0.29 (kg)
-

QM2-2P410G1T (EOL)
QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen4 x 4 , 1 x AQC113C 10GbE NBASE-T port
Dimension (L × W × H): 187 × 19.35 × 68.9 (mm)
Weight: 0.30 (kg)
-

QM2-2P410G2T (EOL)
QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen4 x 4 , 2 x AQC113C 10GbE NBASE-T port
Dimension (L × W × H): 187 × 19.35 × 68.9 (mm)
Weight: 0.30 (kg)
-

QM2-2S-220A
Dual M.2 22110/2280 SATA SSD expansion card;
Dimension (L × W × H): 147.15 × 20.6 × 68.9 (mm)
Weight: 0.30 (kg)
-

QM2-4P-384
Quad M.2 PCIe SSD expansion card; supports up to four M.2 2280 formfactor M.2 PCIe (Gen3 x4) SSDs; PCIe Gen3 x8 host interface; Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled
Dimension (L × W × H): 204.95 × 68.9 × 20.6 (mm)
Weight: 0.32 (kg)
-

QM2-4S-240 (EOL)
Quad M.2 2280 SATA SSD expansion card
Dimension (L × W × H): 204.95 × 68.9 × 20.6 (mm)
Weight: 0.32 (kg)
-

QXG-100G2SF-E810
Dual port 100GbE Network adapter; 2 x QSFP28; Intel E810 Ethernet controller
Dimension (L × W × H): 169.6 × 69 × 18.7 (mm)
Weight: 0.36 (kg)
-

QXG-10G1T
Single-port (10Gbase-T) 10GbE network expansion card, PCIe Gen3 x4, Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled
Dimension (L × W × H): 143 × 193 × 52 (mm)
Weight: 0.53 (kg)
-

QXG-10G2SF-X710
Dual-port SFP+ 10Gb network expansion card; low-profile formfactor; PCIe Gen3 x8
Dimension (L × W × H): 26 × 10.5 × 6 (mm)
Weight: 0.29 (kg)
-

QXG-10G2T
Dual-port 10GBASE-T 10Gb network expansion card; low-profile formfactor; PCIe Gen3 x4
Dimension (L × W × H): 54.5 × 39.5 × 18 (mm)
Weight: 0.24 (kg)
-
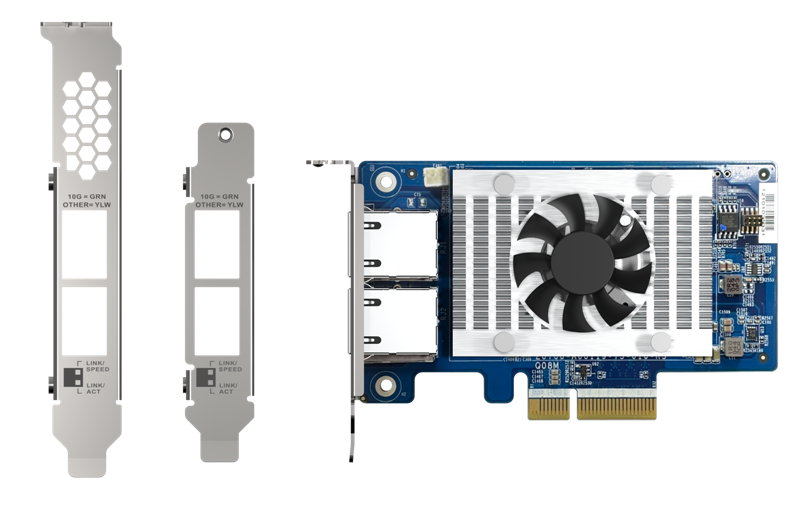
QXG-10G2T-X710
Dual-port 10GbE Network Adaptor, Intel 700 series Ethernet Controller
Dimension (L × W × H): 113.6 × 68.9 × 18.3 (mm)
Weight: 0.24 (kg)
-

QXG-10G2TB (EOL)
Dual-port 10GbE Network Adaptor, Aquantia AQC113C
Dimension (L × W × H): 104.7 × 16.1 × 68.9 (mm)
Weight: 0.28 (kg)
-

QXG-25G2SF-CX6
Dual-port SFP28 25Gb network expansion card; Mellanox ConnectX-6 Lx;low-profile formfactor; PCIe Gen4 x8
Dimension (L × W × H): 120 × 16.5 × 69 (mm)
Weight: 0.15 (kg)
-

QXG-25G2SF-E810
2 port 25GbE(Intel E810-XXVAM2) Network Interface Cards (NIC)
Dimension (L × W × H): 119.3 × 68.9 × 18.1 (mm)
Weight: 0.23 (kg)
-

QXG-2G1T-I225
Single port 2.5GbE 4-speed Network card
Dimension (L × W × H): 67.3 × 68.9 × 25.2 (mm)
Weight: 0.19 (kg)
-

QXG-2G2T-I225
Dual port 2.5GbE 4-speed Network card
Dimension (L × W × H): 81.3 × 68.9 × 25.2 (mm)
Weight: 0.23 (kg)
-

QXG-2G4T-I225
Quad port 2.5GbE 4-speed Network card
Dimension (L × W × H): 104.6 × 68.9 × 24.1 (mm)
Weight: 0.24 (kg)
-

QXG-5G1T-111C
QNAP 5GbE multi-Gig expansion card;Aquantia AQC111C;Gen2 x 1;low profile
Dimension (L × W × H): 145 × 190 × 52 (mm)
Weight: 0.20 (kg)
-
QXG-5G2T-111C (EOL)
QNAP dual port 5GbE multi-Gig expansion card;Aquantia AQC111C;Gen2 x 2;low profile
Dimension (L × W × H): 145 × 190 × 52 (mm)
Weight: 0.20 (kg)
-

QXG-5G4T-111C (EOL)
QNAP Quad port 5GbE multi-Gig expansion card;Aquantia AQC111C;Gen2 x 4;low profile
Dimension (L × W × H): 145 × 190 × 52 (mm)
Weight: 0.23 (kg)
-

QXP-16G2FC
QNAP 2-port 16Gbps fiber channel adapter, PCIe 3.0 x8, SFP+, low profile, w/ SFP+ 16G transceivers
Dimension (L × W × H): 190 × 143 × 50 (mm)
Weight: 0.28 (kg)
-

QXP-32G2FC
QNAP 2-port 32Gbps fiber channel adapter, PCIe 3.0 x8, SFP+, low profile, w/ SFP+ 32G optical transceivers
Dimension (L × W × H): 190 × 143 × 50 (mm)
Weight: 0.28 (kg)
-

QXP-3X4PES
2 ports (SFF-8644) Expansion card; PCIe Gen3 x4 for QNAP PCIe JBOD series
Dimension (L × W × H): 102.65 × 68.9 × 19 (mm)
Weight: 0.11 (kg)
-

QXP-3X8PES
2 ports (SFF-8644 1x2) Expansion card; PCIe Gen3 x8 for QNAP PCIe JBOD series
Dimension (L × W × H): 112.65 × 68.9 × 18.26 (mm)
Weight: 0.17 (kg)
-

RAM-16GDR4ECT0-RD-3200
DDR type: DDR4(288PIN)
Capacity: 16GB
Spec: 1G X 8
Frequency: DDR4-3200
Form(PIN): 288PIN
with ECC Supported: ECC
Power Supply: 1.2V
Dram Organization: 2048M*72
Temperature: 0℃~85℃
Environmental Regulation: Halogen Free
-

RAM-32GDR4ECT0-RD-3200 (EOL)
DDR type: DDR4(288PIN)
Capacity: 32GB
Spec: 2G X 8
Frequency: DDR4-3200
Form(PIN): 288PIN
with ECC Supported: ECC
Power Supply: 1.2V
Dram Organization: 4G*72
Temperature: 0℃~85℃
Environmental Regulation: Halogen Free
-

RAM-32GDR4K0-RD-3200
32GB DDR4 RAM, 3200 MHz, RDIMM
-

RAM-64GDR4ECK0-RD-3200 (EOL)
DDR type: DDR4(288PIN)
Capacity: 64GB
Spec: 4G X 4
Frequency: DDR4-3200
Form(PIN): 288PIN
with ECC Supported: ECC
Power Supply: 1.2V
Dram Organization: 8G*72
Temperature: 0℃~85℃
Environmental Regulation: RoHS
-

RAM-8GDR4ECT0-RD-3200
DDR type: DDR4(288PIN)
Capacity: 8GB
Spec: 1G X 8
Frequency: DDR4-3200
Form(PIN): 288PIN
with ECC Supported: ECC
Power Supply: 1.2V
Dram Organization: 1024M*72
Temperature: 0℃~85℃
Environmental Regulation: Halogen Free



