In today's era of Generative AI (GenAI), High Performance Computing (HPC), and all-flash storage (All-Flash), enterprise requirements for storageunit have surpassed the simple competition of IOPS. When data becomes the fuel for training AI, the accuracy of data represents the intelligence of the model. However, the hidden threat of 'silent data corruption' behind high-speed read/write is endangering the digital assets of enterprises. This article starts from the underlying ZFS technology to analyze how QNAP QuTS hero optimizes its architecture to become the guardian of modern enterprise data.
Invisible threats? What is silent data corruption (Silent Data Corruption)?
When we store a critical financial report or AI training dataset into NAS, the system reports a successful write, and the file manager also shows the file exists. However, after several months, when we try to access it again, the file cannot be opened, or images appear corrupted, and even AI model training frequently encounters unexplained checksum errors. At this point, checking the system logs reveals no hard disk drives errors and no warning lights.
This is static data damage, commonly known as "bit rot". From an engineering perspective, static data damage refers to the situation where data develops imperceptible deviations from its original bit state without any I/O operations, and traditional storage stacks (Disk → RAID → File System) do not provide end-to-end verification mechanisms to detect such errors.
Why does this occur?
This usually happens when data is "idle" during the period of disk, caused by factors including:
- Physical media aging: Magnetic degradation or NAND Flash charge leakage.
- Cosmic rays: High-energy particles impact causing bit flips (0 becomes 1) in memory or on disk.
- Phantom Writes: hard disk drives controller bug leads hard disk drives to report successful writes, but actually fails to write to the correct magnetic area. Traditional RAID cards often cannot detect this type of logic error. Even though some advanced RAID controllers support Patrol Read or background checks, their verification remains at the Block Device layer, unable to interpret upper-layer file semantics, and cannot perform data and mid-level data consistency verification.
- Transmission noise: Minor interference in the signal during transmission through the cable.
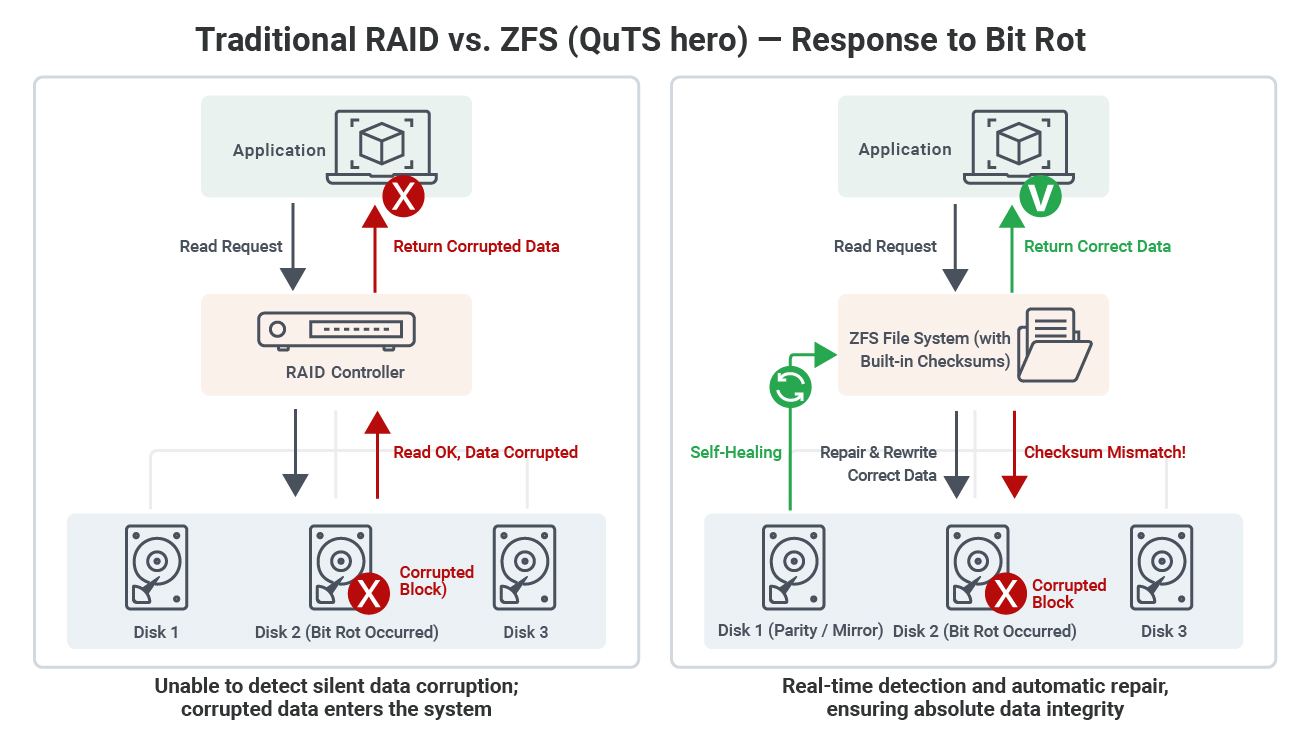
In traditional hardware RAID architecture, the controller usually only intervenes when a hardware failure (Fail) occurs at hard disk drives. If only the content of a single block is corrupted, traditional RAID cannot detect that the data has been damaged during reading, and may even provide incorrect Data Sync to the backup system, resulting in catastrophic chain reactions.
Why is ZFS currently the most mature and extensively proven solution? Advantages of its layered architecture
ZFS (Zettabyte File System) is not just a file system; it is a hybrid of a file system and a volume managervolume. ZFS can simultaneously sense the physical state of the underlyinghard disk drives layer and the logical structure of the upper file system. Strictly speaking, ZFS is not the only system with verification capabilities, but among file systems that offer 'end-to-end verification, self-healing, and enterprise-level maturity' all at once, ZFS remains the most complete implementation to date. Its most important features are as follows:
The first is the Merkle Tree and End-to-End Checksum. If we observe traditional file systems, they separate data and metadata, and often only check metadata when reading. However, the ZFS file system adopts a Merkle Tree-like block chain structure, which allows for pointer binding. When ZFS writes each data block (Data Block), it calculates the checksum for that block. At the same time, it also verifies the parent pointer, and this checksum is not stored in the data block itself, but rather in the “parent pointer” that points to the block. This forms a trust chain that extends upward all the way to the root directory. Since ZFS does not implement a complete encrypted Merkle Tree, but instead forms an irreversible integrity verification chain (Hash Pointer Tree) through the aforementioned “Checksum storage in the parent block” method.
In this situation, ghost writes can be prevented because verification and data are separated from storage. Even if a "ghost write" occurs in hard disk drives, ZFS compares the parent pointer's checksum with the read data during reading and can immediately detect any mismatch.
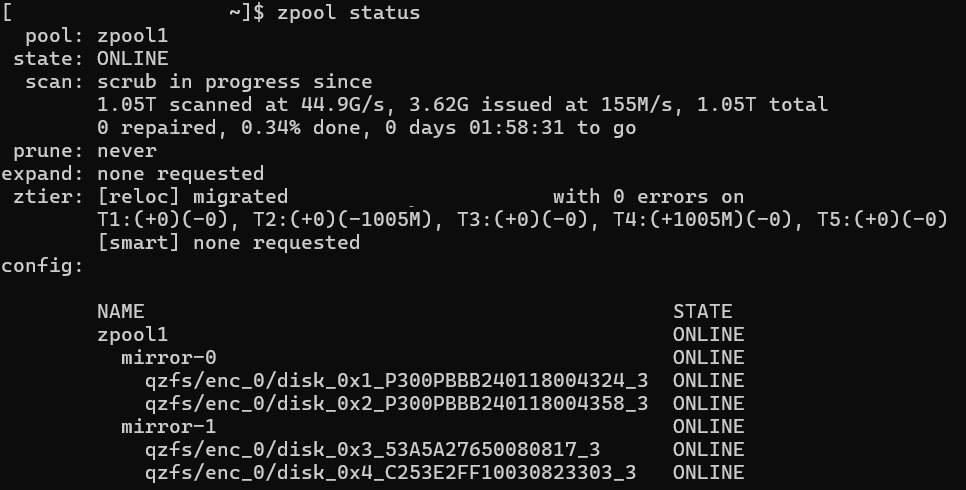
The second feature is the automation of Self-Healing. The ZFS read process is not just “reading,” but “reading plus verification.” It can perform real-time comparison, and when reading data, the CPU immediately calculates the checksum of the read content. If an error is detected, it will intercept the process. If a mismatch is found, the system determines it as silent corruption and refuses to pass the erroneous data to the application, preventing application layer crashes or AI model contamination. In such cases, ZFS will perform background recovery, and the system will automatically use the parity check code (Parity) of RAID-Z or the correct data from the Mirror copy to overwrite and repair the damaged block. In zpool status, administrators can clearly see indicators such as checksum errors and repaired bytes. These data are important references for determining whether hard disk drives has entered the early failure stage.
Although users may not notice, the data read is usually the restored data, but the system will automatically record recovery events (Scrub Error) as a reference for predictive maintenance. Your storageunit or server can use these logs of data to alert and notify you which hard disk drives needs maintenance.
Optimizing architecture and breaking through hardware bottlenecks
For ZFS, QNAP QuTS hero and modern hardware architectures, we need to update the following concepts:
Memory (RAM) is the soul, not just a cache
ARC (Adaptive Replacement Cache) read architecture is a crucial component. ZFS’s read cache (ARC) is located in RAM, and its algorithm is smarter than traditional LRU, allowing it to cache both “recently used” and “most frequently used” data at the same time. Since RAM is hundreds of times faster than NVMe SSD, using it in this part is relatively optimal.
Deduplication (removal of duplicate data) comes with a cost. Although In-line Deduplication in QuTS hero can save space and extend SSD lifespan, it tends to consume more memory.
Traditional guidelines recommend allocating 1GB RAM for every 1TB of data, but the modern best practice is to use a Flash-based Special VDEV to store the Deduplication Table (DDT), reducing the pressure on RAM. If there is no Special VDEV, it is recommended to enable Deduplication only in all-flash environments and scenarios where data deduplication rate is extremely high (such as VDI). In practice, many enterprises enable Dedup without fully evaluating the data deduplication rate, which instead leads to DDT explosion, ARC being squeezed, and ultimately worse performance than not enabling it.
Write cache and proper ZIL configuration
Many people think that adding an M.2 SSD means acceleration. In ZFS, synchronous writes (such as data database transactions) actually rely heavily on ZIL (ZFS Intent Log). For data databases or Virtualization applications, it is recommended to configure high endurance (DWPD > 3) SSD as SLOG (Separate Log) to protect data safety during power outages and accelerate synchronous write performance.
The rise of Special VDEV (Special VDEV)
This is the key to ZFS performance tuning in recent years. QuTS hero supports storing “metadata” and “small files” independently on a set of high-speed SSD RAID (for example, using 2 PCIe NVMe SSD drives in RAID-1), while large files remain on HDD. This allows traditional hard disk drives arrays to achieve nearly full-flash array file traversal and search efficiency.
The role of ZFS in the era of AI and data security
Stable datastorage environment for AI models
In the workflow of RAG (Retrieval-Augmented Generation) and LLM fine-tuning, data quality determines everything. If Bit Rot occurs at the storage base layer, it will lead to deviation in Embeddings vectors. The ZFS file system’s built-in ZFS Scrubbing (data cleansing) mechanism ensures that every element of data fed to the GPU is pure, which is a critical measure for AI applications pursuing precision in medical and financial risk control. In actual AI model deployment, such errors rarely directly cause model training failure, but rather manifest as “gradual decline in accuracy and unstable inference results,” making root cause tracing extremely difficult.
The last line of defense against ransomware, WORM and immutable snapshots
Facing ransomware, backups are no longer enough. What enterprises need is "immutability".
Copy-on-Write (CoW), this ZFS write mechanism ensures that old data blocks are not deleted before being overwritten, making snapshot creation instantaneous and space-efficient.
WORM (Write Once, Read Many) has become a focal point in the market in recent years. By combining the WORM function of QuTS hero, you can set data to be “undeletable or unmodifiable” within a specified retention period. Even if hackers gain access to the management Permission, they cannot encrypt these locked historical snapshots. Under the premise of compliance and system design, for example, we do not assign the WORM retention period License to a single management account, making snapshots immutable and effectively preventing malicious or accidental operations from causing historical data damage.
Hard bottleneck migration: PCIe Gen 5 and DDR5
As NVMe SSD read/write speeds break through 10,000 megabyte/s, traditional CPU and memory bandwidth have become the new bottleneck.
Recommended purchase: Enterprise-grade ZFS solutions should prioritize support for PCIe Gen 4 / Gen 5 channels and DDR5 ECC memory model. The On-die ECC mechanism of DDR5 and ZFS software verification form dual protection, further reducing the risk of system crashes caused by memory bit flips.
From “passive storage” to “active defense”
In this era of data, which is the age of assets, storage systems cannot just be passive warehouses; they must be active guardians. QNAP QuTS hero solves the traditional NAS trust issues that cannot be handled through the ZFS file system. It does not assume that hard disk drives is reliable by default, but strictly verifies every read and write through mathematical algorithms (Checksum).
When deploying ZFS in an information environment, it is recommended to prioritize investing in RAM, as RAM provides the highest marginal benefit for ZFS performance. Next, make good use of Special VDEV by isolating Metadata on SSD in a hybrid storage architecture, which significantly improves overall efficiency. Also, enable regular Scrubbing; it is recommended to perform a complete data scrub at least once a month to proactively detect silent corruption. The frequency of Scrubbing depends on the hard disk drives type (for example, HDD really needs it), the size of pool (large pools require longer Scrub times and may need to be segmented), and I/O load (avoid running during peak periods). Both OpenZFS and QNAP official documentation strongly emphasize performing at least monthly scrubs to prevent data silent corruption.
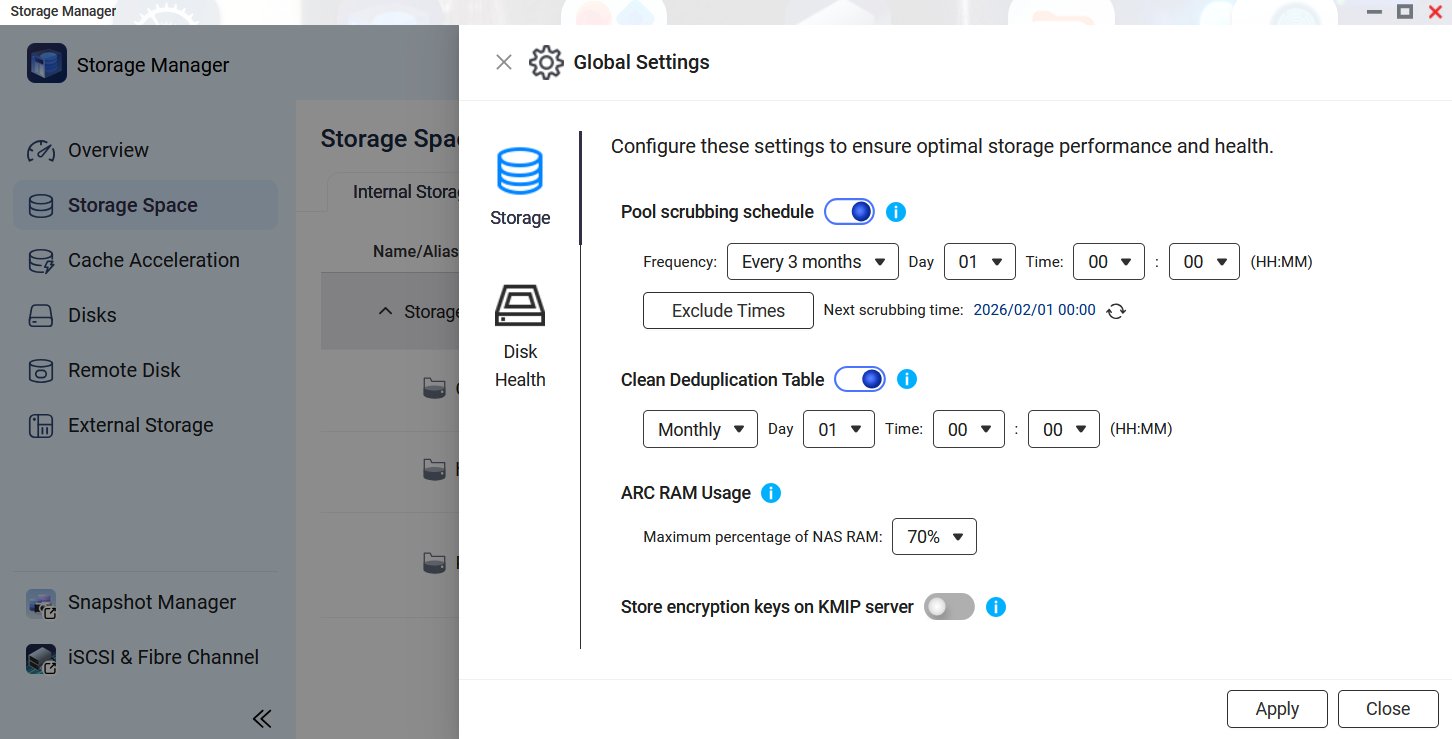
We can manually trigger it using the zpool scrub command, or set up scheduling on systems like Proxmox VE / QNAP QuTS hero. After execution, use zpool status to check the progress and results.
For enterprises pursuing data zero-error, choosing the ZFS system is not only a technical upgrade but also the most crucial insurance investment for business continuity (BCP).