Applicable Products
QTS, QuTS hero
Container Station
Scenario
You want to run large language models (LLMs) locally on your QNAP NAS for private AI chat, code assistance, or document analysis without sending data to the cloud. Ollama is the most popular and beginner-friendly inference engine for this purpose. This tutorial explains how to deploy Ollama on the QNAP NAS using Container Station.
System Requirements
| Requirement | Detail |
|---|
| QNAP App | Container Station 3.x or later |
| NAS Architecture | x86_64 (Intel or AMD CPU)
(Only a few ARM-based models are supported.) |
| Memory | - At least 8 GB (for 3B models)
- At least 16 GB (for 7B models)
|
| Storage Space | - At least 20 GB of extra free storage space in addition to the model file size.
- Use an SSD volume if possible.
|
| GPU (Optional) | Compatible NVIDIA GPUs (see the compatibility list)
GPU should be set to Container Station Mode in the Control Panel. |
Warning
OOM (Out of Memory) Risk
Ollama will attempt to load the entire model into memory by default. If your NAS has only 8–16 GB of RAM, loading a 14B or larger model may exhaust system memory, causing NAS services to become unresponsive or the system to restart.
Data Loss Risk
If you do not mount a persistent volume for /root/.ollama, all downloaded models and configuration will be lost when the container is removed or recreated. Always follow the volume mounting instructions in this tutorial.
Best Practice
- Check the model size against your available RAM in advance.
- Set memory limits to cap container memory usage.
- Start with small models (1B or 3B) and assess system stability before attempting larger models.
Procedure
Method 1: CPU-Only Deployment (No GPU Required)
Create storage folders.
Open File Station and create the following folder to store Ollama model data:
/share/Container/ollama
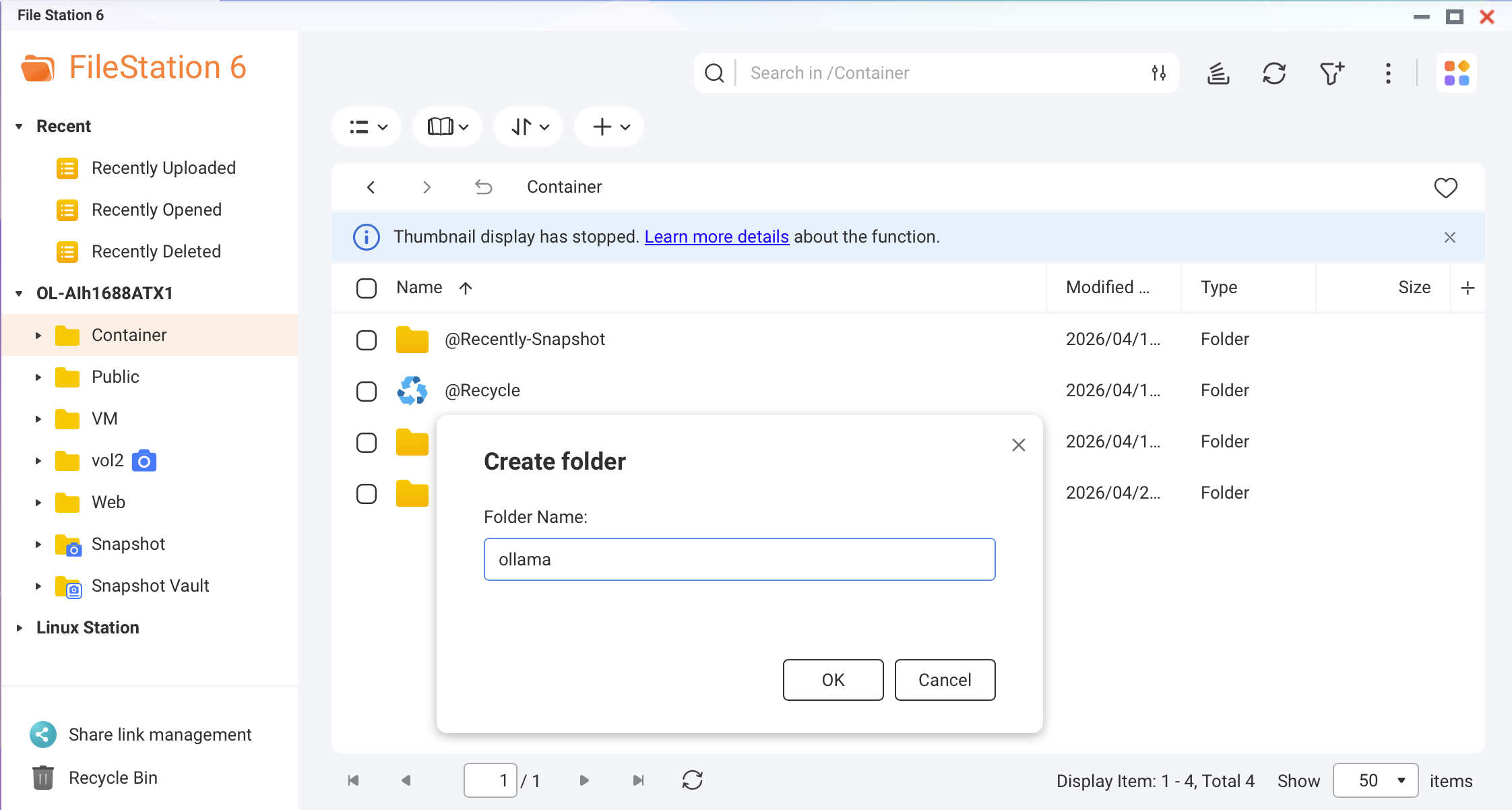 Screenshot: File Station — creating the Ollama folder under /share/Container/
Screenshot: File Station — creating the Ollama folder under /share/Container/
Best Practice
If your NAS has an NVMe SSD cache or SSD volume, create this folder on the SSD. Model loading speed improves by up to 10 times compared to HDDs.
Create a Docker Compose file.
In Container Station, go to Applications > Create. Name the application ollama and paste the following YAML:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
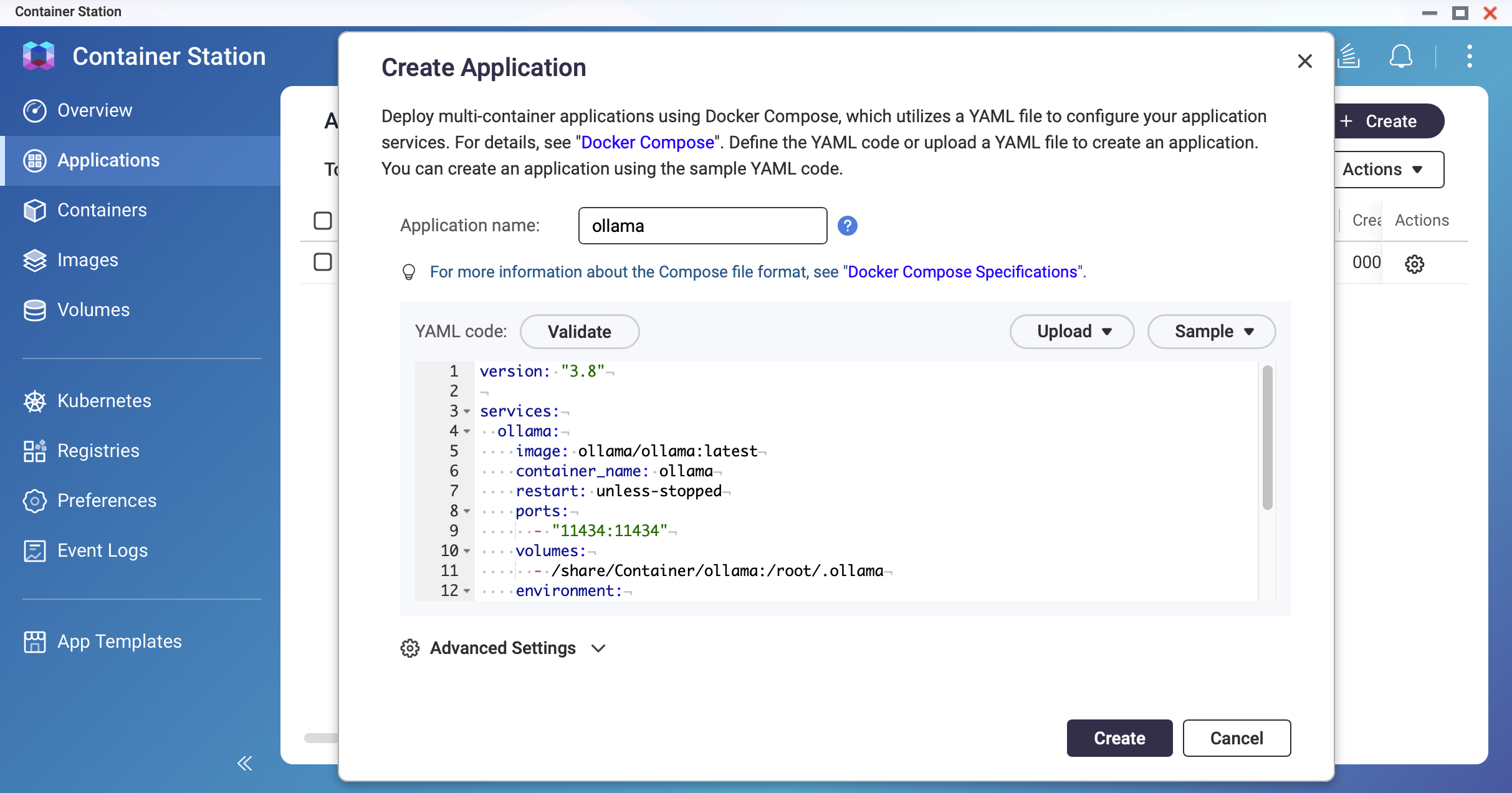 Screenshot: Container Station — Application creation screen with YAML editor
Screenshot: Container Station — Application creation screen with YAML editor
 Screenshot: Container Station — Set the memory limit
Screenshot: Container Station — Set the memory limit
Deploy the container.
Click Create. Container Station will pull the Ollama image and start the container. Wait until the status shows Running.
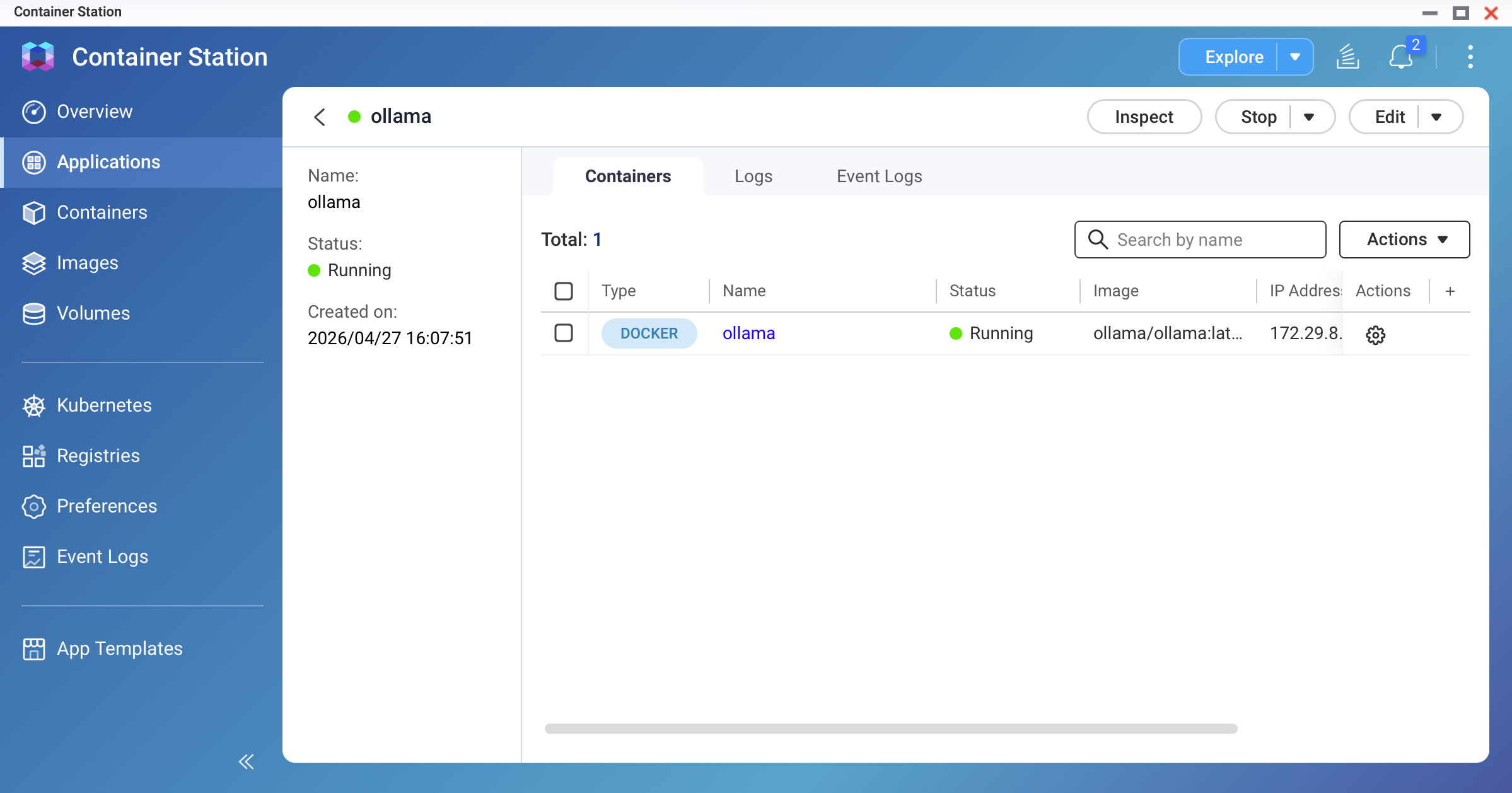 Screenshot: Container Station — ollama container showing "Running" status
Screenshot: Container Station — ollama container showing "Running" status
Pull your first model.
Open the container's Terminal (or SSH into your NAS and exec you Docker) and run:
# For a lightweight 3B model (recommended for first test):
ollama pull llama3.2:3b
# For a standard 9B model (requires 16 GB+ RAM):
ollama pull qwen3.5:9b
The download may take several minutes depending on your internet speed. A 9B Q4_K_M model is approximately 4–7 GB.
Note
- Verify you have sufficient disk space before pulling. Use
ollama list to check existing models and their sizes. - For ARM-based NAS models, we recommend starting with the <1B model to monitor memory usage.
Test the model.
In the container terminal, run:
ollama run qwen3.5:9b
Type a prompt and confirm that you receive a response. Type /bye to exit.
Method 2: NVIDIA GPU-Accelerated Deployment
Note
Additional prerequisites for GPU Mode:
- NVIDIA GPU installed and detected by QTS/QuTS hero
- GPU set to Container Station Mode in the Control Panel
- NVIDIA GPU Driver and NvKernelDriver installed from App Center
Use the GPU-enabled Docker Compose configuration.
Replace the YAML from Method 1 with the following:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
- NVIDIA_VISIBLE_DEVICES=all
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
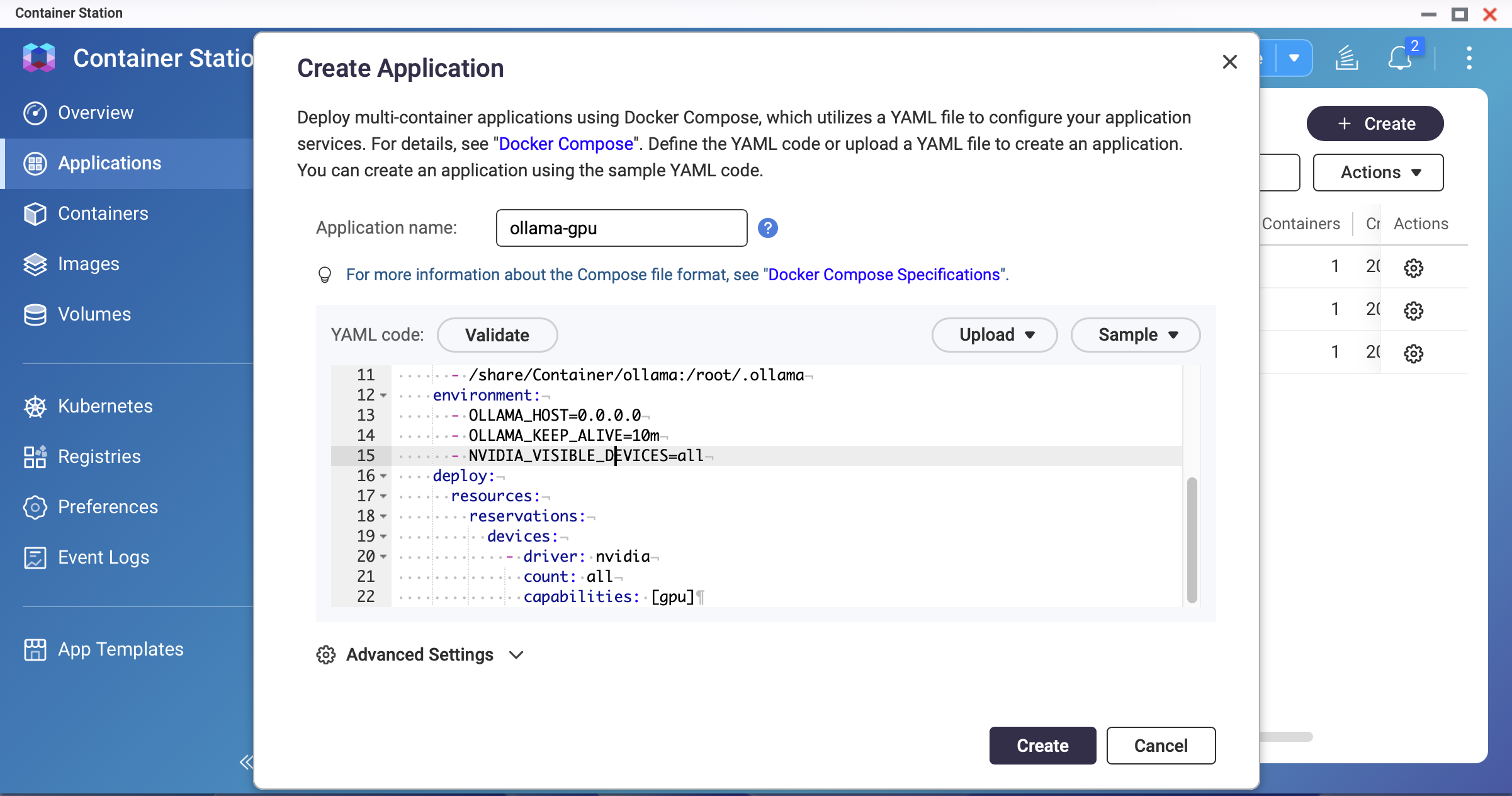 Screenshot: Container Station — GPU-enabled Docker Compose YAML
Screenshot: Container Station — GPU-enabled Docker Compose YAML
Note
QNAP's bundled NVIDIA drivers may be older than the latest release. If the container fails to start with GPU enabled, check the driver version with nvidia-smi on the host and ensure it is compatible with the Ollama image version
Deploy and verify GPU access.
After the container starts, open its terminal and run:
nvidia-smi
You should see your GPU model, driver version, and memory information.
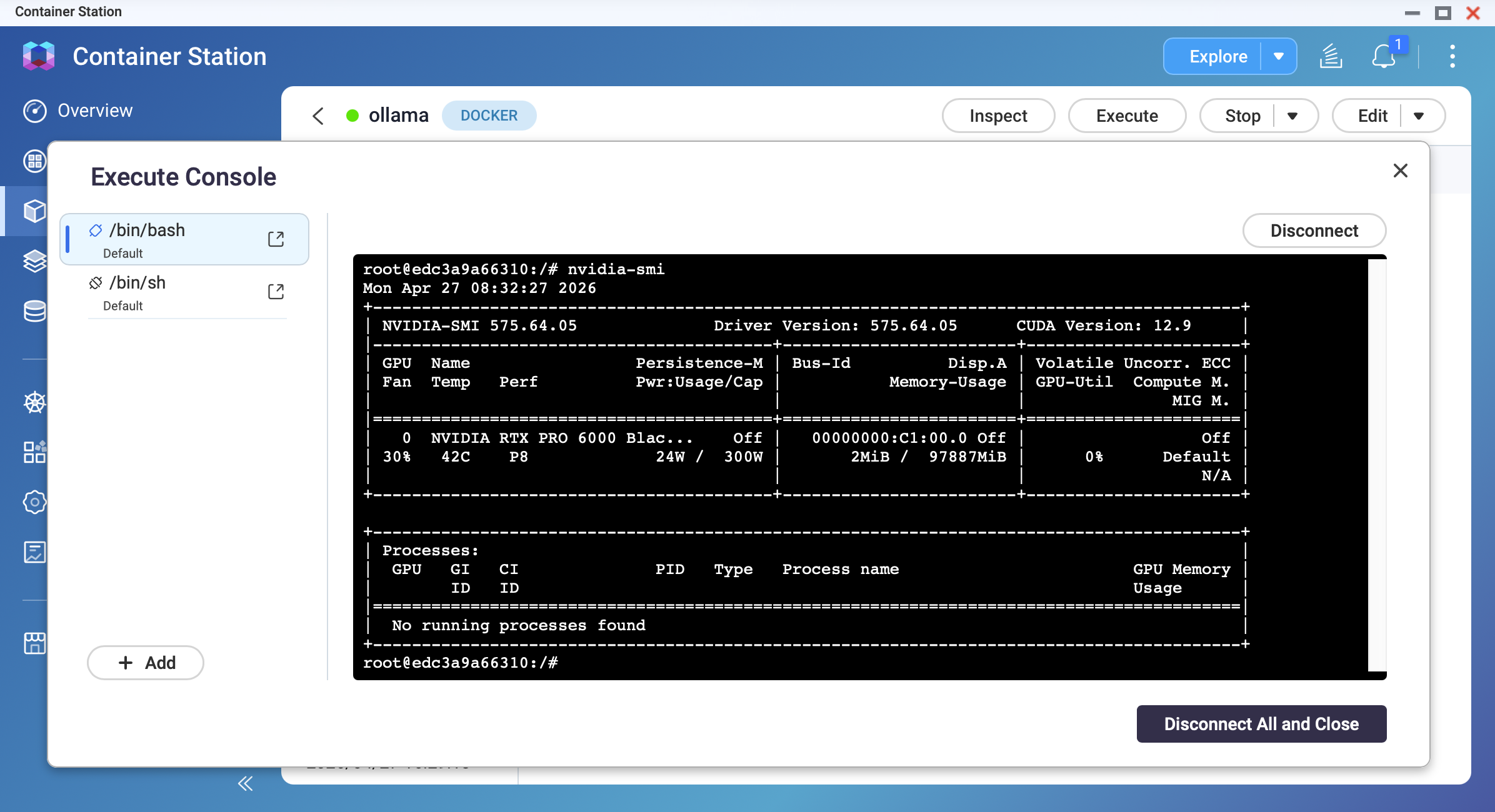
Pull a model and confirm GPU acceleration.
ollama pull qwen3.5:9b
ollama run qwen3.5:9b
While the model is generating a response, open another terminal and run nvidia-smi. You should observe GPU memory usage and GPU utilization increasing.
Result
After completing this tutorial, you will have:
- Ollama running on your QNAP NAS at
http://<NAS-IP>:11434 - Model data persisted in
/share/Container/ollama (survives container rebuilds) - A working LLM accessible via the Ollama API
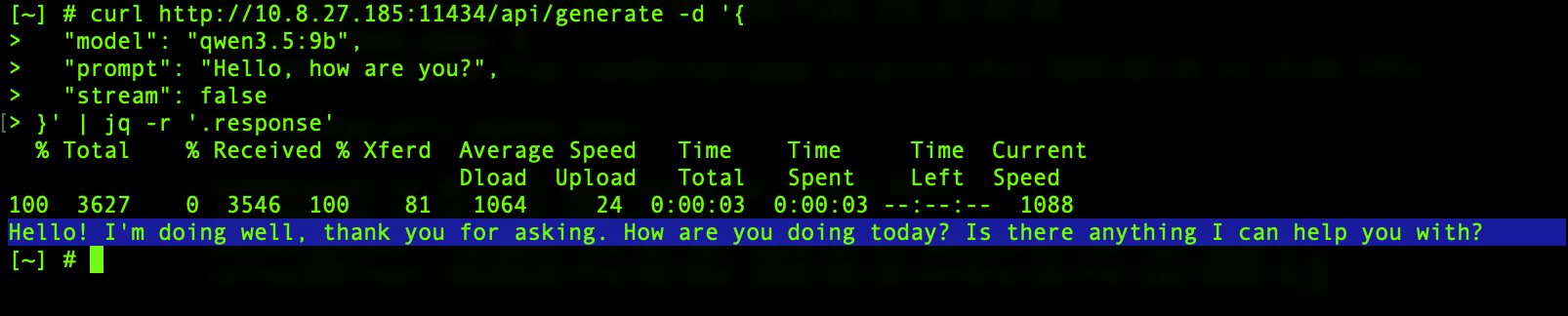
You can test the API from any device on your local network:
curl http://<NAS-IP>:11434/api/generate -d '{
"model": "qwen3.5:9b",
"prompt": "Hello, how are you?",
"stream": false
}'
Important
The OLLAMA_HOST=0.0.0.0 setting exposes the Ollama API on all network interfaces. Do not expose port 11434 to the internet. Use firewall rules or QNAP's network settings to restrict access to your local network only.
Troubleshooting
Container exits immediately after starting
This may be caused by insufficient RAM or GPU driver mismatch. Check container logs in Container Station. Reduce memory limitations or disable GPU mode.
Model pull fails midway
This may result from insufficient disk space or network timeout. Try to free up storage space. Re-run ollama pull; the system resumes from where it stopped.
Response speed is very slow (1–3 tokens per second)
The model may be running on CPU instead of GPU, or the model is too large for your RAM. Verify your GPU access with nvidia-smi inside the container. Try to use a smaller model.
The NAS becomes unresponsive during inference
This can be an "out of memory" issue: the model is consuming all the system memory. We recommend restarting the NAS. Set a memory usage limit in the application. Or use a smaller model.
"Cannot connect to Ollama" message from Open WebUI
This may be caused by a wrong API URL or Docker network isolation. You can use http://ollama:11434 if you are on the same Docker network.
适用产品
QTS, QuTS hero
Container Station
场景
您希望在本地的 QNAP NAS 上运行大型语言模型(LLM),用于私人 AI 聊天、代码辅助或文档分析,而无需将数据发送到云端。Ollama 是此目的下较受欢迎且易于上手的推理引擎。本教程解释了如何使用 Container Station 在 QNAP NAS 上部署 Ollama。
系统要求
| 要求 | 详细信息 |
|---|
| QNAP 应用程序 | Container Station 3.x 或更高版本 |
| NAS 架构 | x86_64(Intel 或 AMD CPU)
(仅支持少数基于 ARM 的型号。) |
| 内存 | - 至少 8 GB(适用于 3B 型号)
- 至少 16 GB(适用于 7B 型号)
|
| 存储空间 | - 除了模型文件大小外,至少需要额外 20 GB 的存储空闲空间。
- 如果可能,使用 SSD 卷。
|
| GPU(可选) | 兼容的 NVIDIA GPU(参见兼容性列表)
GPU 应在控制台中设置为 Container Station 模式。 |
警告
内存不足(OOM)风险
Ollama 默认会尝试将整个模型加载到内存中。如果您的 NAS 只有 8–16 GB 的 RAM,加载 14B 或更大的模型可能会耗尽系统内存,导致 NAS 服务无响应或系统重启。
数据丢失风险
如果您没有为/root/.ollama挂载持久卷,所有下载的模型和配置将在容器被移除或重新创建时丢失。请务必遵循本教程中的卷挂载说明。
较佳实践
- 提前检查模型大小与可用内存的匹配情况。
- 设置内存限制以限制容器的内存使用。
- 从小模型(1B 或 3B)开始,评估系统稳定性,然后再尝试更大的模型。
步骤
方法 1:仅 CPU 部署(无需 GPU)
创建存储文件夹。
打开File Station,创建以下文件夹以存储 Ollama 模型数据:
/share/Container/ollama
截图:File Station — 在 /share/Container/ 下创建 Ollama 文件夹
较佳实践
如果您的 NAS 有 NVMe SSD 缓存或 SSD 卷,请在 SSD 上创建此文件夹。与 HDD 相比,模型加载速度提高至多 10 倍。
创建一个 Docker Compose 文件。
在 Container Station 中,进入应用程序 > 创建。命名应用程序为ollama并粘贴以下 YAML:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
截图:Container Station — 应用程序创建界面与 YAML 编辑器
截图:Container Station — 设置内存限制
部署容器。
点击创建。Container Station 将拉取 Ollama 镜像并启动容器。等待状态显示为运行中。
截图:Container Station — Ollama 容器显示“运行中”状态
拉取您的较高个模型。
打开容器的终端(或通过 SSH 进入您的 NAS 并执行 Docker),然后运行:
# 对于轻量级 3B 模型(推荐用于测试):
ollama pull llama3.2:3b
# 对于标准 9B 模型(需要 16 GB 以上的 RAM):
ollama pull qwen3.5:9b
下载可能需要几分钟,具体取决于您的网速。9B Q4_K_M 模型大约为 4 到 7 GB。
注意
- 在拉取之前,请确认您有足够的磁盘空间。使用
ollama list检查现有模型及其大小。 - 对于基于 ARM 的 NAS 型号,我们建议从 <1B 模型开始以监控内存使用情况。
测试模型。
在容器终端中运行:
ollama run qwen3.5:9b
输入提示并确认您收到响应。输入/bye以退出。
方法二:NVIDIA GPU 加速部署
注意
GPU 模式的额外先决条件:
- 安装并由 QTS/QuTS hero 检测到的 NVIDIA GPU
- 在控制台中将 GPU 设置为 Container Station 模式
- 从 App Center 安装 NVIDIA GPU 驱动程序和 NvKernelDriver
使用启用 GPU 的 Docker Compose 配置。
用以下内容替换方法一中的 YAML:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
- NVIDIA_VISIBLE_DEVICES=all
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
截图:Container Station — 启用 GPU 的 Docker Compose YAML
注意
QNAP 捆绑的 NVIDIA 驱动程序可能比全新版本旧。如果启用 GPU 的容器无法启动,请在主机上使用nvidia-smi检查驱动程序版本,并确保其与 Ollama 镜像版本兼容
部署并验证 GPU 访问。
容器启动后,打开其终端并运行:
nvidia-smi
您应该看到您的 GPU 型号、驱动程序版本和内存信息。
拉取模型并确认 GPU 加速。
ollama pull qwen3.5:9b
ollama run qwen3.5:9b
在模型生成响应时,打开另一个终端并运行nvidia-smi。您应该观察到 GPU 内存使用和 GPU 利用率增加。
结果
完成本教程后,您将拥有:
- 在您的 QNAP NAS 上运行的 Ollama,位于
http://<NAS-IP>:11434 - 模型数据保存在
/share/Container/ollama(容器重建后仍然存在) - 通过 Ollama API 可访问的工作 LLM
您可以从本地网络上的任何设备测试 API:
curl http://<nas-ip>:11434/api/generate -d '{"model":"qwen3.5:9b","prompt":"Hello, how are you?","stream": false}'
重要提示
OLLAMA_HOST=0.0.0.0设置在所有网络接口上公开 Ollama API。不要将端口 11434 暴露给互联网。使用防火墙规则或 QNAP 的网络设置限制访问仅限于本地网络。
故障排除
容器启动后立即退出
这可能是由于内存不足或 GPU 驱动不匹配导致的。检查 Container Station 中的容器日志。减少内存限制或禁用 GPU 模式。
模型拉取中途失败
这可能是由于磁盘空间不足或网络超时导致的。尝试释放存储空间。重新运行ollama pull;系统将从停止的地方继续。
响应速度较为慢(每秒 1-3 个标记)
模型可能在 CPU 上运行而不是 GPU,或者模型对您的内存来说太大。使用nvidia-smi在容器内验证您的 GPU 访问。尝试使用较小的模型。
在推理过程中 NAS 无响应
这可能是“内存不足”问题:模型正在消耗所有系统内存。我们建议重启 NAS。在应用程序中设置内存使用限制。或者使用较小的模型。
Open WebUI 显示“无法连接到 Ollama”消息
这可能是由于错误的 API URL 或 Docker 网络隔离导致的。如果您在同一个 Docker 网络中,可以使用http://ollama:11434。



